softmax with CUDA worklog - pt 1 (Naive to Kernel Fusion)
It's becoming pretty evident to me that none of these algos are intuitive. You know that von Neumann quote
"Young man, in mathematics you don't understand things. You just get used to them."
Yeah that's pretty much what I think about cuda.
My head has been floating trying to understand softmax and the optimizations that are done in the wild to make this tiny simple looking thing (it's so not) fast.
So what this post actually is: a worklog, not a tutorial. I'm not here to polish syntax. I want numbers and profiler truth for row-wise softmax on a GPU: start from a PyTorch-style naive stack (many passes, temps), mirror that as naive CUDA with shared-memory reductions, rip those out for warp shuffles, then try register fusion when a whole row can live in registers. Code stays stripped on the page; the repo has the rest. Full tree: my GitHub.
Benchmarks and TFLOPS tables below are from an A100 SXM4 (15.6 TFLOPS FP32, ~1315 GB/s memory, 40 GB VRAM, nvcc 12.8, ~12 GB/s PCIe). When I say NCU, those screenshots are from my laptop's GeForce MX450 (same questions, smaller GPU).
I'm very thankful to AIs for helping me figure CUDA out faster. Learning this stuff without that help feels like a distant, bitter memory.
Outline
- Intuition: what softmax does and where it shows up (attention, huge
N) - Softmax kernel progression
Intuition
I'm a fairly simple human brain. I like breaking things down till I have absolute clarity about the concepts, so let's think about what softmax means by itself and in the context of LLMs.
Historically, early neural networks (e.g., the Frank Rosenblatt perceptron in the 1960s) used step functions. Those produce zero gradients almost everywhere, which makes gradient-based learning impossible.
Modern models instead use smooth functions. Sigmoid was the early solution for binary outputs. Softmax is its multi-class generalization.
First, the definition.
Softmax takes a vector of real numbers (logits) and outputs a probability distribution.
For an input vector :
- Input (): Logits (can be to ).
- Numerator (): The "unnormalized probability" (strictly positive). Makes everything positive and magnifies relative differences.
- Denominator (): rescales everything so the output sum equals 1.
Basically softmax turns arbitrary scores into a probability distribution. The exponential sharpens differences. Small gaps in logits become large gaps in probability mass.
From the Attention Is All You Need paper:
is similarity scores (dot products). Softmax turns those scores into weights that sum to 1 across the row: if you want 90% on token X you have to take it from somewhere else. If Y is only slightly ahead of X in logit land, softmax can still put a lot of mass on Y (it sharpens). Same de-noising flavor as before.
It forces the model to make a decision on what is important right now, ignoring the background hum of irrelevant words.
That softmax is applied row-wise. Rows don't talk to each other for this step. So you get embarrassing parallelism and, on hardware, you usually hit memory before you run out of ALUs.
Training snapshot (why vocab-sized rows hurt)
Tiny language-model picture: context "The cat sat on the...", target token "Mat". The model outputs logits, we softmax, we get something like "Mat" 5%, "Dog" 94%, "Hat" 1%. Cross-entropy with the one-hot target only cares about the true class probability:
Backward with softmax + CE gives a gradient shaped like : big negative on the right class when you're wrong (push logits up), big positive on wrong classes you overbelieved (push down), tiny on the rest. As the model gets better, those deltas shrink and updates get gentle until you're basically converged.
For my physics brain, softmax is a hydraulic distributor: forward pass forces probability fluid to sum to 1; backward measures pressure vs where the fluid should have gone; gradients shove weights to widen the right pipe and choke the wrong ones.
Other people have derived the full backward pass properly. I'm skipping that here on purpose. Softmax on paper is a small formula. On a GPU it's mostly a question of how often you drag the same row through DRAM. The sections below are all row softmax kernels (one row at a time in spirit). Attention is the place in models where N gets huge; that's the motivation, not the code path I'm optimizing in this part.
Softmax
The real problem isn’t what softmax computes. It’s how many times we move the same data to compute it.
Everything below is one progression: same math, less pointless traffic. When I write 5N for the naive CUDA path I mean per row, counting each element of that row: three full reads from global memory (max pass, exp pass, normalize pass) and two full writes (park exp, write final), so five element-sized touches. Later steps try to cut those passes, not just make reductions prettier.
I thought of making excalidraw-style diagrams but passed: plenty exist already, and a static picture lies about how parallel this stuff feels. Use your brain's eye after the numbers.
1a. Naive Softmax
This is the “ground truth” implementation (clean, readable, and completely unaware of hardware).
This naive implementation I lift from the Triton docs.
def naive_softmax(x):
x_max = x.max(dim=1)[0] # (M, N) -> (M, )
z = x - x_max[:, None] # (M, N) + (M, ) -> (M, N)
num = torch.exp(z) # (M, N) -> (M, N)
den = num.sum(dim=1) # (M,N) -> (M, )
ret = num / den[:, None] # (M, N) + (M, ) -> (M, N)
# 5 (M, N) + 2 (M, ) reads
# 3 (M, N) + 2 (M, ) writes
return retProfiles below are NCU-style captures on the setup described at the top; the headline is always the same: DRAM-bound softmax.




Readout
- Figure 1: Elementwise work dominates time; that's where the bottleneck shows up first.
- Figure 2: Memory throughput ~86%, compute ~12%. Classic memory-bound softmax.
- Figure 3: L1/L2 hit rate is low; DRAM is basically full; kernel-only micro-opts won't save you. You need less traffic (fusion), not cleverer math in isolation.
- Figure 4: Occupancy is fine. The machine isn't starved of warps; it's starved of bytes per useful op.
Though mathematically correct, there are real problems with this version. The biggest one: we're making multiple passes over the same row. For a model like Llama2-7B that's 32,000 (vocab size) × 4,096 (d_model) = 131,072,000 elements. That's a lot of numbers to keep reading from memory over and over.
On top of that, we're fetching from global memory constantly and creating multiple temporary tensors along the way.
But nothing is as sacrilegious when programming GPUs as not utilizing the GPU properly. We're completely DRAM-limited, barely utilizing the compute capacity of this thing (~12%).
So let's drop down to CUDA
1b. Naive Softmax CUDA
Before doing any optimizations, I wanted a reference CUDA kernel that I could expand on. This is the simplest version I could think of, a direct translation of the three-pass approach into a single kernel with shared memory tree reduction.
You can check the code for this here
Although simple to write and reason about, this approach is very inefficient in terms of memory bandwidth:
- Find max → Read N
- Compute exp → Read N, Write N (intermediate buffer)
- Sum and divide → Read N, Write N
Total: 5N memory operations (3 reads + 2 writes per row, counted per element).
On top of that: so many __syncthreads per row (shared-memory tree reductions in passes 1 and 2), and 256 floats of smem as reduction scratch only. The row itself is never kept across passes. Pass 1 drops the values after the max; pass 2 must re-read from VRAM, park exp in global memory, then pass 3 reads it again. The tree reduction also idles most threads after each round (128 → 64 → ... → 1 active).
Same story in the profiler for this CUDA port:

Bandwidth-dominated, as expected. The same story as the PyTorch version, softmax is inherently data-movement-bound because it's doing very little math per byte moved.
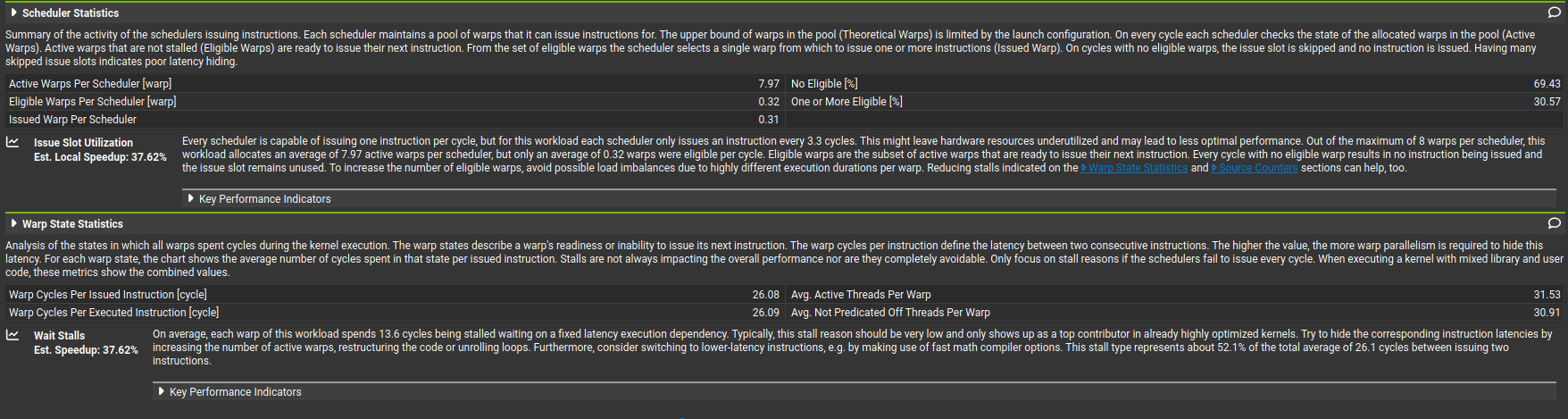
Wait stalls are high because DRAM fetches are increasing latency and preventing proper scheduling. The threads are spending most of their time just... waiting for data to arrive from VRAM.

Caching is quite low. With three separate passes over the same row, we're evicting data from cache before we get to reuse it.

The compiler is already telling us to use fusion.
Here's the comparison against torch softmax:
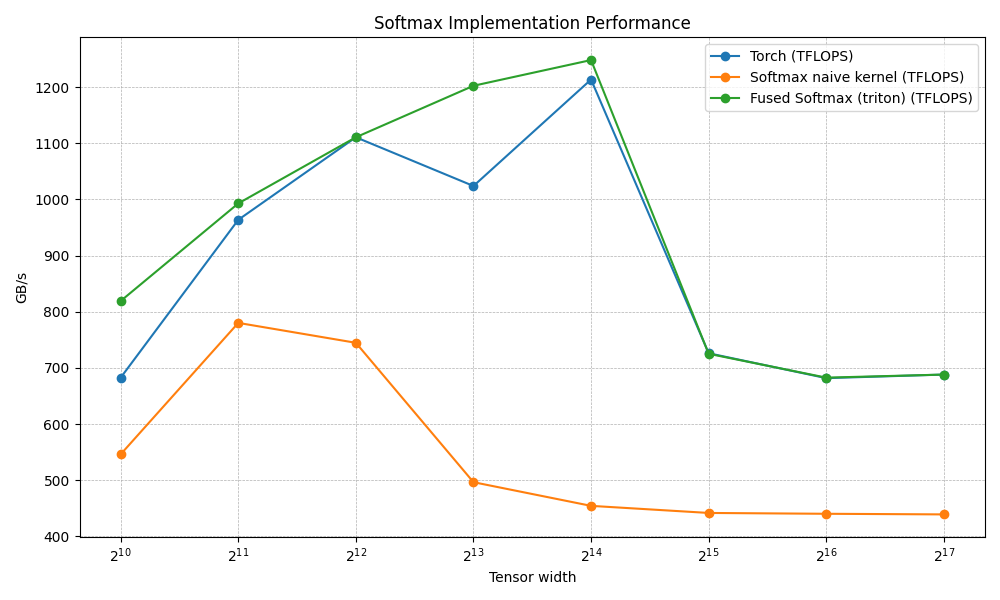
N Torch (TFLOPS) Softmax naive kernel (TFLOPS) Fused Softmax (triton) (TFLOPS)
0 1024.0 682.666643 546.133347 819.200021
1 2048.0 963.764689 780.190482 992.969689
2 4096.0 1110.779627 744.727267 1110.779627
3 8192.0 1024.000003 496.484845 1202.495407
4 16384.0 1213.629628 454.322335 1248.304772
5 32768.0 726.160639 441.691675 725.156318
6 65536.0 681.778954 440.208233 682.666643
7 131072.0 688.154899 439.102173 688.154899Still quite below torch's implementation, but the hope is to get close to it (surpass it?) as we iterate through the optimizations.
But look at the numbers closely. Torch gets pretty useless after a certain threshold of model size, while Triton stays rock solid. Like, what?! Ok, nvm, I'm pretty sure I'll surpass torch's performance. The real goal is to match Triton. Someday I'll dig into the MLIR magic that makes it so fast.
The profiling made one thing painfully clear: tree reduction in shared memory could be improved. the many sync barriers per row, most threads sitting idle during the reduction rounds, and we're still at 5N (3 reads + 2 writes to VRAM per element along the row). The math is cheap. Data movement and sync are what's killing us. We parallelized the work but not the memory traffic.
Next move: rip out the smem trees and use warp shuffles for the reductions. That should murder barriers and smem traffic inside the reduction. Spoiler: 5N to global memory stays until we actually fuse the passes.
2. Coalesce and Warp Reductions
Threads within a warp execute in lockstep. They can communicate through registers with very low latency, no block-wide synchronization needed. NVIDIA gives us __shfl_down_sync to reduce values across registers within a warp, completely bypassing shared memory for that step.
The code now looks like this: warpReduction.cu
Same three-pass VRAM pattern as naive. Only the reductions move from smem trees to warp shuffles:
- Find max → Read N
- Compute exp → Read N, Write N
- Sum and divide → Read N, Write N
Total: still 5N memory operations. Shuffles do not remove the second full read of the row or the exp buffer round-trip.
What actually changed: 4 __syncthreads per row (down from 18), 8 floats of smem (down from 256), and better thread activity during reduction (warps stay busy in shuffle rounds instead of halving active threads each tree level).
What didn’t change: DRAM traffic. Still 5N, still the bottleneck.
And then I ran the benchmark again and got this:
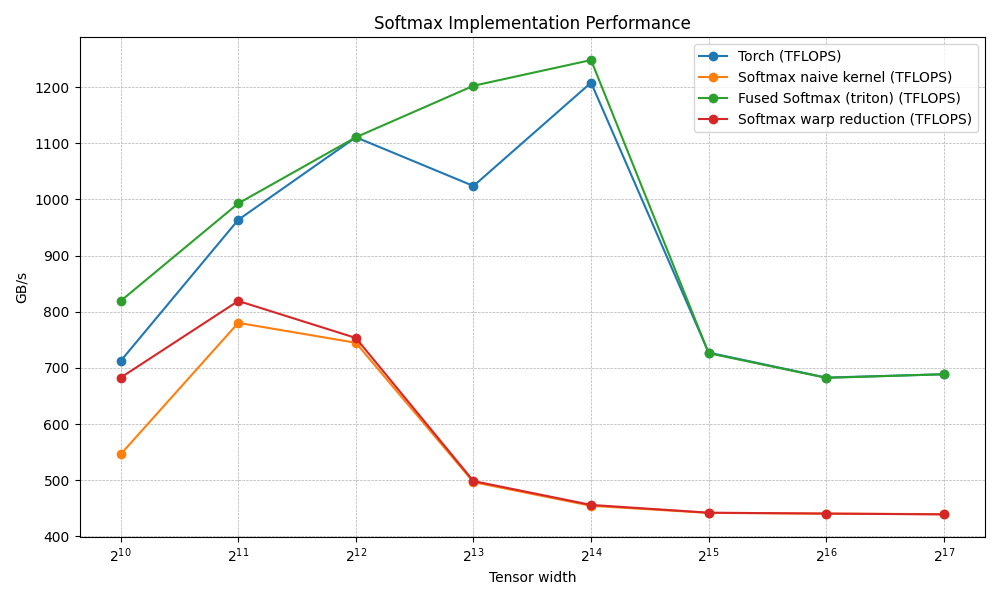
N Torch (TFLOPS) Softmax naive kernel (TFLOPS) Fused Softmax (triton) (TFLOPS) Softmax warp reduction (TFLOPS)
0 1024.0 712.347810 546.133347 819.200021 682.666643
1 2048.0 963.764689 780.190482 992.969689 819.200021
2 4096.0 1110.779627 744.727267 1110.779627 753.287353
3 8192.0 1024.000003 496.484845 1202.495407 498.372634
4 16384.0 1208.036903 454.322335 1248.304772 455.902599
5 32768.0 727.167804 441.691675 726.160639 442.064099
6 65536.0 682.666643 440.393118 682.222536 440.485619
7 131072.0 688.719891 439.470242 688.606818 439.010274Huh?
All these lines of complicated code and... nothing changed. The numbers are basically identical. What's going on? Of course: 5N is still 5N. I never removed the extra full-row reads or the exp buffer round-trip. I only made the reduction cheaper on paper.

Still mostly bandwidth-bound. we optimized the reduction (compute side), but the bottleneck was never the reduction. It's the 3 reads + 2 writes to VRAM per element that dominate wall-clock time. Shuffles are faster than tree reduction, sure, but the kernel spends most of its life waiting on DRAM, not reducing.

The one redeeming thing: L1/L2 shared memory hit rates are higher. The reduced smem footprint (8 floats vs 256) means more capacity is available for caching, so we're at least winning on that front.

Could potentially increase the number of active warps. lower smem usage means the SM can schedule more blocks concurrently.
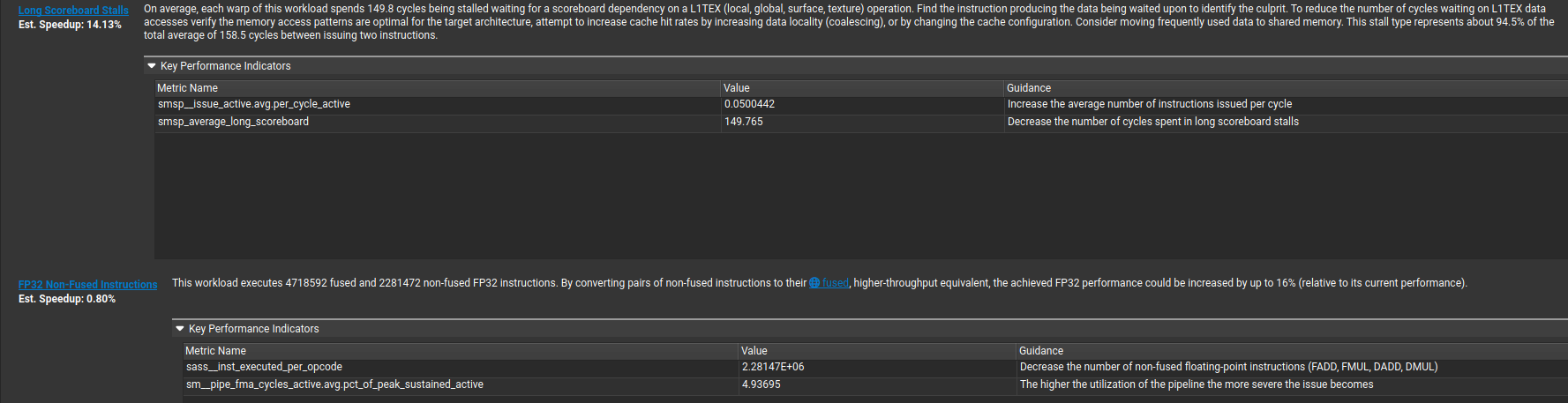
And here's the nail in the coffin: "On average, each warp of this workload spends 149.8 cycles being stalled waiting for a scoreboard dependency on a L1TEX (local, global, surface, texture) operation." That's no bueno. The warps are just sitting there waiting for data from the DRAM to come back/write to.
So the lesson is clear: If you're memory bound, optimizing compute does nothing.
3. kernel fusion and loop unroll
The goal: touch VRAM once.
Registers are the only place where performance actually happens.
The idea is simple:
- load once from VRAM
- never go back to VRAM
- do everything in registers
- write once back to VRAM
If each warp owns one row and the row fits in registers, we can load the data once, do all the math (max, subtract, exp, sum, divide) without ever writing intermediates to global memory, and write the final result once.
The code for this is here.
One warp owns one row: load once, max / exp / sum / normalize in registers (butterfly shuffles for max and sum, no smem), write once. No intermediate global buffer.
VRAM accounting (when the row actually fits)
- Load row + local max → Read N (only DRAM read of logits)
- Max, exp, sum, normalize → 0 DRAM traffic (all in registers)
- Store softmax → Write N (only DRAM write)
That is 2N element-touches per row vs 5N on the naive path. The exp values that naive wrote to global and read back never leave the register file here.
Barriers: 18 → 0 (one warp per row, hardware lockstep shuffles).
Smem: 256 floats of reduction scratch → 0 for this kernel; the SM's smem budget is free for other work.
Memory ops: naive mostly moved 4 bytes per scalar load/store; fused uses float4 (16 bytes per op), which tends to feed the bus better.
Some "fused" stacks still walk logits twice from DRAM (separate max pass vs exp pass) if the full row cannot live in registers. That is roughly 3N (two reads + one write) when you skip a global exp buffer. Here the row sits in buf[], so logits see one read.
Register pressure (where the fairy tale ends)
float4 buf[NUM_PACKS] with NUM_PACKS = N/(32×4) = N/128 (32 lanes × 4 wide vectors). Roughly 4 registers per float4 for buf[] alone, so 4 × NUM_PACKS before rowMax, rowSum, and temps. N=4096: 32 float4s → ~128 regs for buf[], still under a typical 255 regs/thread ceiling (NCU can still print ~128 for the whole kernel when live ranges overlap cleanly). N=8192: 64 float4s → 256 regs for buf[] by itself, you go off the cliff into local memory (DRAM behind L1). The clean 2N picture turns into "bandwidth bound again, uglier access than streaming naive." Bigger rows need a different story; that's for part 2.
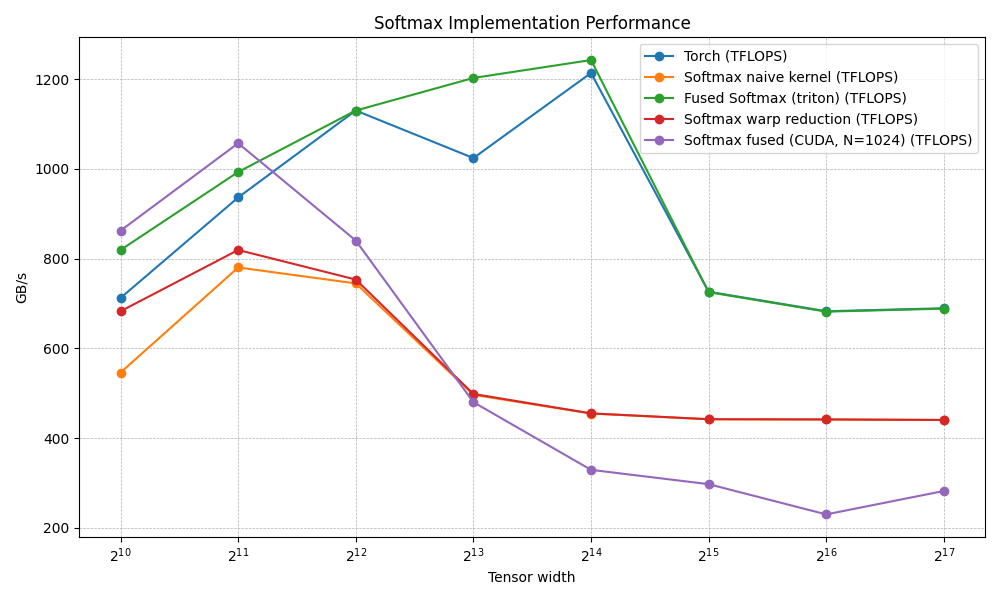
N Torch (TFLOPS) Softmax naive kernel (TFLOPS) Fused Softmax (triton) (TFLOPS) Softmax warp reduction (TFLOPS) Softmax fused (CUDA, N=1024) (TFLOPS)
0 1024.0 712.347810 546.133347 819.200021 682.666643 862.315828
1 2048.0 936.228546 780.190482 992.969689 819.200021 1057.032272
2 4096.0 1129.931006 744.727267 1129.931006 753.287353 840.205157
3 8192.0 1024.000003 496.484845 1202.495407 498.372634 480.117194
4 16384.0 1213.629628 454.716373 1242.388591 455.111095 329.326630
5 32768.0 726.160639 442.064099 725.156318 442.064099 297.383998
6 65536.0 682.666643 441.505698 681.778954 441.598667 230.001315
7 131072.0 689.285785 440.485597 688.493782 440.393118 282.216660Same sweep as the earlier tables: fixed batch layout, row length N scanning the left column. When the register file cooperates, this kernel really does one global read + one global write per element and skips the extra buffers.
what ncu tells us
I grabbed this table with the same tensor shape for all four kernels (the run that produced the Duration row, fixed M and N, same dtype). Numbers first, then interpretation.
Metric Naive Warp Reduction Fused (CUDA) Fused (Triton)
─────────────────────────────────────────────────────────────────────────────────────
Duration (ms) 3.49 3.49 2.64 1.40
DRAM Throughput 85.87% 85.93% 83.55% 85.49%
Compute (SM) Throughput 6.38% 4.72% 2.40% 4.09%
Achieved Occupancy 98.93% 98.86% 45.73% 94.87%
Registers Per Thread 18 16 128 37
L1/TEX Hit Rate 19.65% 19.50% 3.15% 0.00%
L2 Hit Rate 40.12% 40.16% 51.52% 50.01%
Warp Cycles / Instruction 194.26 238.12 333.12 168.80
Local Mem Spill Overhead 0% 0% 100% 0%
Branch Efficiency 100% 100% 0% 100%Everything is memory-bound. DRAM throughput sits around 83% to 86% on all four kernels. Compute throughput is 2% to 6%. The SM is almost always waiting on DRAM, not doing arithmetic. Warp cycles per executed instruction (168 to 333) make that concrete.
Swapping NAIVE shared-memory reductions for WARP shuffles killed barriers and smem traffic inside the reduction, but that was never the real bottleneck. The naive path was always 5N global traffic (three full reads and two full writes of each element along the row, same accounting I used above). Shuffles beat __syncthreads() on paper, but if the SM spends most of its life waiting on DRAM anyway, you never see it on the stopwatch. I optimized the wrong thing.
FUSED (CUDA) in this table:
-
Registers per thread: 128. Cap is 255. With 128 threads per block that is 16,384 registers per block. The SM has 65,536 registers total, so at most 4 blocks stay resident. Theoretical occupancy tanks to 50%, achieved to 45.73%, next to 98.86% for warp reduction at 16 registers per thread. Then
Local Memory Spilling Request Overhead = 100%: every spill goes to local memory (VRAM). 464.90 spill requests per SM per launch. So much for "one VRAM read, one VRAM write." The compiler is doing a pile of secret DRAM round trips through the back door. -
Warp cycles per instruction: 333.12 fused CUDA vs 194.26 naive. Fused stalls more per instruction because spilled registers hit memory with uglier patterns than naive's streaming loads.
-
L2 hit rate edges up for fused (51.52% vs 40.12%) because the spill/reload ping-pong eventually warms L2. Small comfort.
-
Branch efficiency 0% is its own bug: grid-strided loop +
if (row < M). Picking a grid that divides the work cleanly nukes that.
Triton fused in the same row: 37 registers per thread, 1.40 ms duration. CUDA fused: 128 registers, 2.64 ms. At N = 1024 Triton is already 1.9× faster. Their compiler tiles the row instead of parking the whole thing in registers at once, which caps register pressure and keeps occupancy at 94.87%.
What I'm taking away
- Row softmax on these GPUs is DRAM-bound long before it is FMA-bound.
- 5N traffic (three global reads + two global writes per element for the naive story) dominates until you fuse enough to drop to 2N in the happy case.
- Warp shuffles fix sync and smem overhead; they do not delete the extra full-row reads or the exp buffer hop. Same 5N, same wall time.
- Register fusion buys the 2N ideal until
buf[]spills; then you are slower than naive again and NCU screams spills. - Triton already knows how to stay off that cliff at N = 1024 because it does not try to hold the entire row in thread registers at once.
Still plenty left: beat Triton for real, maybe poke CuteDSL, benchmark against Liger, all that fun. Part 2 when I've survived the next layer of spills.